TiCDC 架构和数据同步链路解析
11 July 2022
TiCDC 是 TiDB 生态中的一个数据同步工具,它通过拉取 TiKV 的变更日志实现数据的增量同步。它除了可以将 TiDB 的数据同步至 MySQL 兼容的数据库之外,还提供了同步至 Kafka 的能力,支持 canal 和 avro 多种开放消息协议供其他系统订阅数据变更。
基本概念
以下这些都是理解 TiCDC 架构之前需要熟悉的基本概念,主要是对 TiDB 内部的一些组件和概念的解释。
- TiDB: 下文中提到的 TiDB 主要是指它作为是一个计算层的抽象提供执行 SQL 的能力,没有真实的存储数据。
- TiKV: 一个支持 ACID 的键值数据库,它可以作为 TiDB 的存储层。
- Region: 它是 TiKV 数据移动的基本单位,可以将它认为是一组键值对集合。每个 Region 被复制到多个 TiKV 节点。
- 两阶段提交:一种分布式算法,它协调所有参与分布式原子事务的进程,决定是否提交或中止(回滚)该事务。
- StartTs: TiDB 在开始两阶段提交时获取到的一个全局唯一递增的时间戳作为当前事务的唯一事务 ID,这里称为该事务的 start_ts。
- CommitTs: TiDB 在提交两阶段提交事务时获取到另外一个全局唯一递增的时间戳作为该事务的 commit_ts。
什么是 CDC?
CDC 的全称为 Change Data Capture,它是指从源数据库捕获数据并且将其同步到其他数据库或者应用程序的过程。它作为一种很常见的数据集成方式被大量的应用在数据仓库中。当然任何的数据库系统都可以构建自己的 CDC,比如 SQL Server 的 CDC。TiCDC 就是专属于 TiDB 的 CDC,它的上游只能是 TiDB,但是它的下游可以是其他 MySQL 兼容的数据库系统,也可以是消息队列。
通过 TiCDC 我们可以实现 TiDB 集群之间的灾备和数据同步,也可以将 TiDB 的数据集成进其他数据处理系统。
TiCDC 的架构
我们知道了 CDC 需要获取变更并将它同步给下游的系统,那对于 TiCDC 来说它就需要从 TiKV 拉取变更,因为 TiDB 集群写入的每一条数据最终都会被持久化到 TiKV 上。下面我们就从架构上来看一看 TiCDC 如何将数据从 TiKV 拉取并同步到下游系统中。
我们将一个 TiCDC 节点称为一个 Capture,一个 Capture 的可能由下面两个组件组成:
- Owner: 一个 TiCDC 集群中的某个节点会被选举成为 Owner,它会负责处理任务的调度和 DDL 事件的处理。
- Processor: 其他非 Owner 节点则会启动 Processor 进程来处理 Owner 调度过来的同步任务,它主要负责处理 DML 事件。
注意:Owner 节点也会启动 Processor 进程来处理同步任务,但是整个集群中有且仅有一个 Owner。
另外我们注意到,在 TiKV 系统中也存在一个叫做 TiKV CDC 的组件,它就是数据同步的起点,所有的行变更都是由该组件通过 gRPC Stream 推送给 TiCDC 节点。
我们先来看一看 Owner 组件的主要职责:
- Owner 会启动 TiCDC 中的 DDL Puller 从 TiKV 拉取 DDL 的变更,并且对收到的变更数据进行编解码,将其转化为 DDL SQL 语句然后通过 DDLSink 写入下游系统。
- Owner 会通过 scheduler 组件向其他节点发送命令进行同步任务调度,让其启动 Processor 进程开始同步数据。 在 TiCDC 中我们把这种任务称为 Changefeed。每个 Changefeed 可能会根据配置同步多张表,Owner 会根据每个节点负责同步的表数量将一个 Changefeed 中的表平均的分配到多个节点。
- Owner 会负责收集各个节点的同步进度,计算和统计全局的同步进度。
当其他节点收到来自 Owner 的同步命令之后,它们就会启动上图所示的 Processor 进程:
- 每个 Processor 会负责同步一个任务。
- 当节点收到来自 Owner 的命令之后,会启动 Processor 进程,每个 Processor 会根据收到的任务详情启动 Table Pipeline,它作为一个流水线会负责以表为单位从 TiKV 拉取数据、排序数据、组装数据和写入数据到下游。
根据上述的架构我们知道 TiCDC 同步数据的核心流程是 Table Pipeline,那我们就来看一看一条 DML 被执行之后,如何从 TiKV 被捕获并同步至下游。
数据同步链路
我们可以把 Table Pipeline 细化成四个部分:
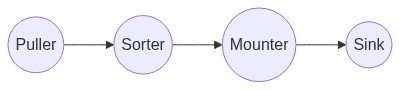
- Puller: 负责与 TiKV CDC 组件建立 gRPC 连接并捕获数据
- Sorter: 负责对拉取到的乱序数据进行排序,让其以表为单位按照事务提交时间进行排序
- Mounter: 根据事务提交时的表结构信息解析和填充行变更,将行变更转化为 TiCDC 能直接处理的数据结构
- Sink: 将 Mounter 处理过后的数据进行编解码,转化为 SQL 语句或者 Kafka 消息写入下游
一个例子
假设我们现在建立如下表结构:
CREATE TABLE TEST(
NAME VARCHAR (20) NOT NULL,
AGE INT NOT NULL,
PRIMARY KEY (NAME)
);
+-------+-------------+------+------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+------+---------+-------+
| NAME | varchar(20) | NO | PRI | NULL | |
| AGE | int(11) | NO | | NULL | |
+-------+-------------+------+------+---------+-------+
此时我们在 TiDB 先后执行这两条 DML:
INSERT INTO TEST (NAME,AGE)
VALUES ('Jack',20);
UPDATE TEST
SET AGE = 25
WHERE NAME = 'Jack';
下面我们就来看一看这两条 DML 会通过什么样的链路写入下游。
数据写入到 TiKV
在 TiDB 执行 SQL 之后数据最终是以 key-value 的形式写入了 TiKV,我们可以暂时忽略掉 TiKV 具体如何写入数据的细节,从 key-value 的形式来看一看最终写入到 TiKV 的数据。
- 执行第一条插入语句
INSERT INTO TEST (NAME,AGE)
VALUES ('Jack',20);
+------------+-----------------+
| Key | Value |
+------------+-----------------+
| TEST_Jack | Jack | 20 |
+------------+-----------------+
- 执行第二条更新语句
UPDATE TEST
SET AGE = 25
WHERE NAME = 'Jack';
+------------+-----------------+
| Key | Value |
+------------+-----------------+
| TEST_Jack | Jack | 25 |
+------------+-----------------+
我们在示例中为了方便理解,将 key 简化为表名_主键的形式,但是请注意 TiKV 并不会真的按照这种格式存储数据。它实际上会为每个表分配 TableID、RowID 和 IndexID 来组成 key。
当这些数据按照 key-value 的形式写入到 TiKV 之后,TiCDC 就可以与 TiKV 建立 gRPC 连接然后进行数据拉取。
Puller 从 TiKV 拉取
我们在架构解析中提到 Puller 负责与 TiKV CDC 组件建立 gPRC 连接然后拉取数据,那我们就先来看一看 gRPC 的数据结构和接口定义。
完整 proto 定义,请参考该文件。
TiCDC 与 TiKV 之间的数据交互只有一个接口:
service ChangeData {
rpc EventFeed(stream ChangeDataRequest) returns(stream ChangeDataEvent);
}
TiCDC 发送一个请求,然后与 TiKV 建立一个 gRPC Stream,源源不断的接收推送过来的数据。
TiCDC 发送的请求信息:
message ChangeDataRequest {
uint64 region_id = 2;
metapb.RegionEpoch region_epoch = 3;
bytes start_key = 5;
bytes end_key = 6;
...
}
在请求信息中我们省略了很多无关信息,TiCDC 在与 TiKV 建立连接时主要需要关注的是:
- Region 信息,因为在 TiKV 中,数据都被分散存储在每个 Region 及其副本上,所以从 TiKV 的角度看 TiCDC 拉取数据的单位是 Region。
- start_key 和 end_key,因为从 TiCDC 的角度看,TiCDC 拉取数据的单位是 Table,所以当一个 Region 出现多个表数据时,TiCDC 可以通过 start_key 和 end_key 来指定拉取的范围。
TiKV 通过请求信息扫描出数据之后,会将结果作为一个 ChangeDataEvent 返回给 TiCDC:
message Event {
enum LogType {
UNKNOWN = 0;
PREWRITE = 1;
COMMIT = 2;
ROLLBACK = 3;
COMMITTED = 4;
...
}
message Row {
uint64 start_ts = 1;
uint64 commit_ts = 2;
LogType type = 3;
enum OpType {
UNKNOWN = 0;
PUT = 1;
DELETE = 2;
}
OpType op_type = 4;
bytes key = 5;
bytes value = 6;
bytes old_value = 7;
...
}
}
message ResolvedTs {
repeated uint64 regions = 1;
uint64 ts = 2;
}
message ChangeDataEvent {
repeated Event events = 1;
ResolvedTs resolved_ts = 2;
}
在返回结果中,我们最需要关注的是 Row。我们在上面写入的数据就会被转换成:
+-------------+--------------+------------+---------+--------------+------------------+------------------+
| start_ts | commit_ts | type | op_type | key | value | old_value |
+-------------+--------------+------------+---------+--------------+------------------+------------------+
| 1 | 2 | COMMITTED | PUT | TEST_Jack | Jack | 20 | null |
| 3 | 4 | COMMITTED | PUT | TEST_Jack | Jack | 25 | Jack | 20 |
+-------------+--------------+------------+---------+--------------+------------------+------------------+
我们可以看到 Insert 语句扫描出的数据只有 value 没有 old_value,而 Update 语句则被转化为一条既有 value 又有 old_value 的行变更数据。
除了数据之外,我们可以看到还有一种叫做 ResolvedTs 的事件,这是一个在 TiCDC 系统中很重要的标识时间点,可以看到我们收到 Row 事件中都带有 commt_ts 这样的时间戳,而 ResolvedTs 事件的下发就意味着小于等于这个时间点提交的数据已经全部下发给 TiCDC,并且以后不会再有早于这个时间点的数据发送至 TiCDC,所以 TiCDC 可以以此为界限来尝试将收到的数据同步至下游。
这样这两条数据就成功的被 Puller 拉取到了 TiCDC,但是因为 TiDB 中一张表的数据会被分散到多个 Region 上,所以 Puller 会与多个 TiKV Region Leader 节点建立连接,然后拉取数据。那实际上 TiCDC 拉取到的变更数据可能是乱序的,我们需要对拉取到的所有数据进行排序才能正确的将事务按照顺序同步到下游。
Sorter 进行排序
假设我们现在除了上述的两条数据之外,在该表上又进行了其他的写入操作,并且该操作的数据在另外一个 Region。最终 Puller 拉到的数据如下:
+--------------------------------------------+-----------------------------------------------------+
| Region1 | Region2 |
+--------------------------------------------+-----------------------------------------------------+
| | ts3: Test_Mick -> Mick | 18 |
| ts2: TEST_Jack -> Jack | 20 | |
| ts2: Resolved | |
| ts3: TEST_Jack -> Jack | 25 | ts3: Resolved |
| ts3: Resolved | |
+--------------------------------------------+-----------------------------------------------------+
我们可以看到拉取到的数据并不是按照 commit_ts 严格排序的,我们需要根据 commit_ts 作为依据将它们进行排序,最终得到如下的数据:
+--------------------------------------------+
| Events |
+--------------------------------------------+
| ts2: TEST_Jack -> Jack | 20 |
| ts2: Resolved |
| ts3: TEST_Jack -> Jack | 25 |
| ts3: Test_Mick -> Mick | 18 |
| ts3: Resolved |
+--------------------------------------------+
这样严格按照 commit_ts 排好顺序的事件就可以接着往下游同步了,同时我们也将 ResolvedTs 事件穿插在排序好的数据中,这是因为它也需要作为一种特殊事件被写入到后置的组件中,它会作为一个标志事件被用于驱动后置组件的下发行为。例如:后置组件在收到 commit_ts 等于 2 的 ResolvedTs 事件之后就可以将之前收到的 commit_ts 小于等于 2 的 DML 事件写入下游并且等待执行完成。
但是下发之前我们需要先对数据做一些转换,因为我们现在收到的是从 TiKV 中扫描出的 key-value,我们无法直接将它转化为 SQL 写入下游,它们实际上只是一堆 bytes 数据。
Mounter 进行解析
当我们拿到这些 bytes 数据之后,我们需要对它进行一些解析,将它还原成按照表结构组织的数据。我们在架构中可以注意 Processor 也会通过 DDLPuller 来拉取表信息,并且将这些信息汇总在一个叫做 SchemaStorage 的结构中。Mounter 会从该结构中找到某个行变更当时的表结构信息,然后将其从 key-value 转化为携带表信息的结构体。
type RowChangedEvent struct {
StartTs uint64
CommitTs uint64
Table *TableName
ColInfos []rowcodec.ColInfo
Columns []*Column
PreColumns []*Column
IndexColumns [][]int
...
}
可以看到,该结构体中还原出了所有的表和列信息,并且 Columns 和 PreColumns 就对应于 value 和 old_value。当 TiCDC 拿到这些信息之后我们就可以将数据继续下发至 Sink 组件,让其根据表信息和行变更数据去写下游数据库或者生产 Kafka 消息。
Sink 进行下发
当一条条 RowChangedEvent 被下发至 Sink 组件之后,我们就可以将其转化为 SQL 或者特定消息格式的 Kafka 消息。在架构中我们可以看到有两种 Sink,一种是接入在 Table Pipeline 中的 TableSink,另外一种是 Processor 级别共用的 ProcessorSink。它们在系统中有不同的作用:
- TableSink 作为一种 Table 级别的管理单位,缓存着要下发到 ProcessorSink 的数据,它的主要作用是方便 TiCDC 按照表为单位管理资源和进行调度
- ProcessorSink 作为真实要与数据库或者 Kafka 建立连接的 Sink 负责 SQL/Kafka 消息的转换和同步
我们再来看一看 ProcessorSink 到底如何转换这些行变更:
- 如果下游是数据库,ProcessorSink 会根据
RowChangedEvent中的 Columns 和 PreColumns 来判断它到底是一个Insert、Update还是Delete操作,然后根据不同的操作类型,将其转化为 SQL 语句,然后再将其通过数据库连接写入下游:
/*
因为只有 Columns 所以是 Insert 语句。
*/
INSERT INTO TEST (NAME,AGE)
VALUES ('Jack',20);
/*
因为既有 Columns 且有 PreColumns 所以是 Update 语句。
*/
UPDATE TEST
SET AGE = 25
WHERE NAME = 'Jack';
- 如果下游是 Kafka, ProcessorSink 会作为一个 Kafka Producer 按照特定的消息格式将数据发送至 Kafka。 以 Canal-JSON 为例,我们上述的 Insert 语句最终会以如下的 JSON 格式写入 Kafka:
{
"id": 0,
"database": "test",
"table": "TEST",
"pkNames": [
"NAME"
],
"isDdl": false,
"type": "INSERT",
...
"ts": 2,
"sql": "",
...
"data": [
{
"NAME": "Jack",
"AGE": "25"
}
],
"old": null
}
这样一条条 DML 就会通过 Sink 源源不断的写入到下游了。虽然我们的数据源源不断的往下同步了,但是对于用户来说应该如何确定同步的进度呢?
如何监测数据同步进度?
用户在使用 TiCDC 的时候会很关心数据的同步进度,因为 TiCDC 是一个增量同步工具,上游会有源源不断的写入,TiCDC 会不断的处理和同步数据。所以可以把它认为是一个流处理系统。在流处理系统中我们常常会引入 watermark 或者 checkpoint 的概念来监测数据同步的进度。
想要理解这个 checkpoint/watermark 的概念,我们先要梳理一下在流处理系统中的两类时间:
-
处理时间(Processing time):处理时间是指执行相应操作的机器的系统时间。对于 TiCDC 来说,它在内部的每个组件中完成数据拉取、转换等操作的时间就可以认为是处理时间。
-
事件时间(Event time):事件时间是指该事件发生时的逻辑时间。对于 TiCDC 来说,它指的是某个行变更在事务中被提交时的 commit_ts。
从定义上来看,对用户洞察系统同步进度的有效时间是事件时间,我们可以通过当前 TiCDC 写完的行变更的 commit_ts 来确定同步的进度或者延迟。这就是我们的 checkpoint。
TiCDC 就是通过 CheckpointTs 来标识数据同步的进度,而它的反馈就是从 Sink 组件来的,因为 TiCDC 接收数据并处理完成的标识就是 Sink 组件将该 SQL/Kakfa 消息写入到了下游并且收到了回复,这样我们就认为这条数据已经同步完成了。
我们通过统计每个节点上 Processor 中的 Sink 组件的进度,就能计算出整个任务当前的同步进度或延迟。
总结
我们通过一个 Table Pipeline 走完了一条 DML 的完整同步链路。在上述的文章中我们主要讨论的是 DML 的同步链路。我们忽略了 TiCDC 中如何处理 DDL 同步、如何进行表调度、如何利用 PD 进行元信息管理和保证集群高可用等问题。希望下次我能够再深入到这些问题中,为大家分享我们的解决方案。
参考链接
— Rustin Liu